
Introduction
Commonly used machine learning and deep learning algorithms learn correlations between data. These models are extremely powerful and are being used in different areas like computer vision, natural language processing, and forecasting.
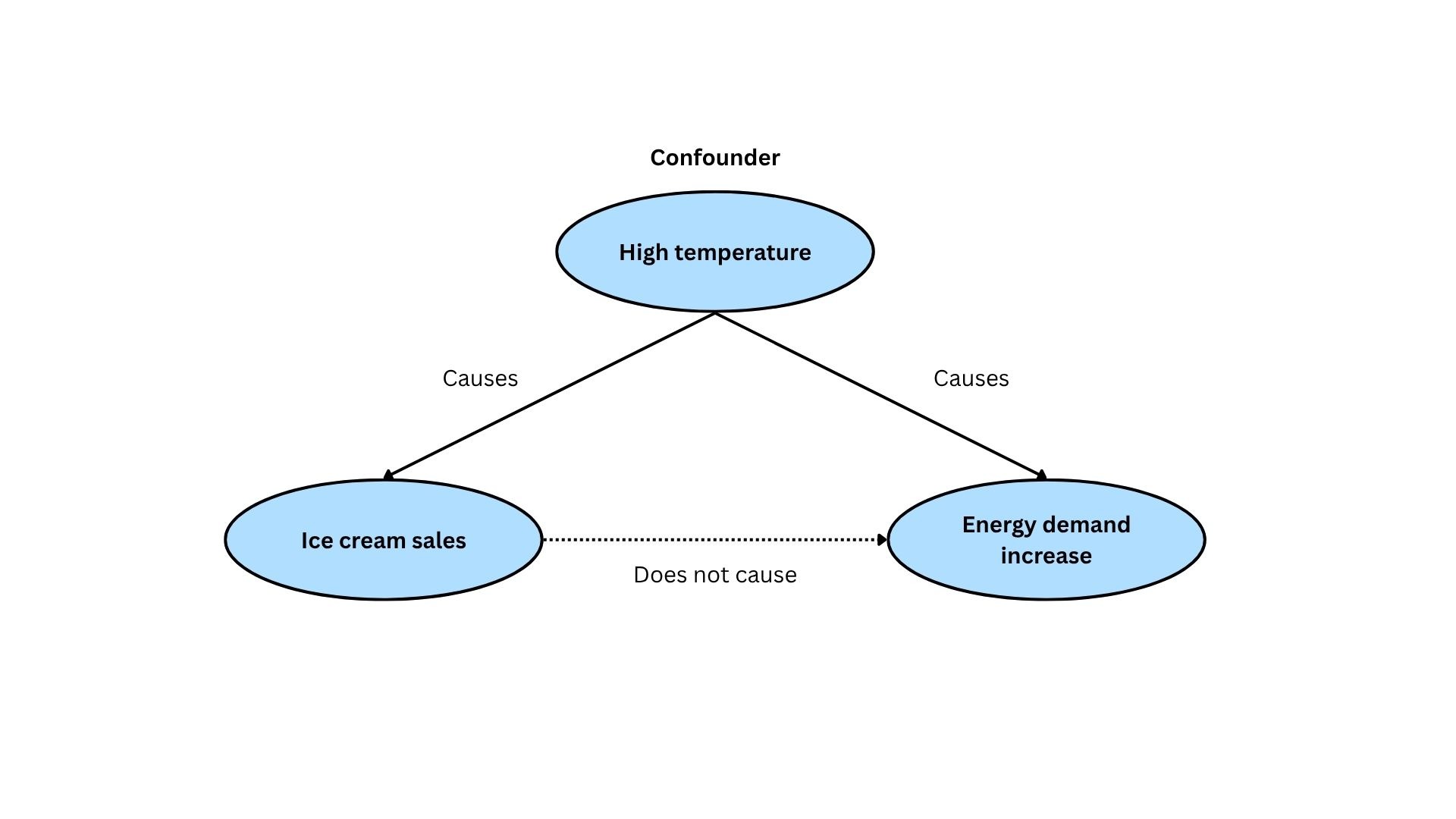
Nonetheless, correlation does not imply causation. Take, for instance, a hot summer day [1]. It is very likely that energy demand might increase. It is also possible that ice cream sales surge. These two variables are correlated, or in simpler terms, “in sync”. However, neither is the energy demand driving ice cream sales, nor is it the other way around.
Of course, this example is fairly simple to detect. The temperature rise is what causes both the increase in ice cream sales and energy demand. In the context of causal inference, temperature acts as a confounder when we are trying to understand whether there is a causal effect between energy demand and ice cream sales.
In other cases, it is less obvious. Take, for instance, the development of drugs. Here, it is crucial to determine whether the patients healed because they took the medicine or whether other factors were at play. In this case, randomized A/B tests are generally used to determine causality. However, in many real-world settings, this approach is not feasible, ethical, or affordable. We cannot always randomly assign people to different treatments, business decisions, policies, or environmental conditions just to observe what happens.
In these cases, we often need to work with observational data which was not collected in a controlled experiment and this makes causal analysis more difficult. In addition, these situations often involve large and complex datasets, with many nonlinear interactions between variables, which is where machine learning shines.
Here is where causal machine learning becomes relevant. But, what is Causal ML exactly? It’s an umbrella term for approaches that explicitly incorporate causal assumptions into machine learning workflows. This allows us to understand the cause-and-effect in certain processes and situations, and to build more robust models. While traditional machine learning is often excellent at forecasting outcomes, causal ML focuses on understanding interventions (i.e. what happens when we actively change something), counterfactuals (i.e. what would have happened under a different decision or condition), and the mechanisms behind observed data.
Causal machine learning: Fundamentals, applications and limitations
Causal graph
One of the key features of causal machine learning is that assumptions of what variables influence each other are explicitly defined. These are represented via directed acyclic graphs (DAGs), which are also known as causal graphs. These graphs, as the name suggests, should not contain any cycle, so a variable cannot eventually cause itself through a loop as such:
A → B → C → D → A
In simple terms, DAGs provide the causal map behind the data. They guide the machine learning model by clarifying what needs to be adjusted for, what should not, and which assumptions are being made.
Example use case
One use case for causal ML is invariant feature learning. Let’s take image classification for different species as an example. Many animals are commonly found in a specific habitat, for instance, cows in pastures. If the dataset contains only pictures with that background, the model might fail to recognize the cow outside its natural habitat. In other words, the model learned the spurious association between the surrounding pasture and the label [2].
The directed acyclic graph for this situation would be the following [3]:

To solve this, one approach is to use "generative interventions" [3]. Instead of collecting more biased data, they steer generative AI models to actively manufacture interventions on the images, such as changing camera viewpoints, removing backgrounds and altering scene context. By training on these intervened images (plus the original ones), the model is forced to stop relying on the background. Instead, it focuses on the true causal features of the object, such as its physical shape.
To learn more about other use cases of causal machine learning, such as causal supervised learning, causal explanations and causal fairness, we refer to “Causal Machine Learning: A Survey and Open Problems “ [2].
Limitations
As stated previously, one of the key characteristics of causal machine learning is that causality assumptions are baked into the models. Making these assumptions can result in bias amplification and harming external validity compared to purely statistical models.
Another one is the lack of ground-truth evaluation data. In order for the models to be benchmarked, interventional data (such as randomized control trials) is required. Generating it involves interacting with the environment, which can be expensive, unethical or time consuming, compared to passively observed datasets like those used to train LLMs or other predictive deep learning models [2].
Conclusions
As discussed in this article, causal machine learning seeks to amplify machine learning techniques by incorporating true cause-and-effect relationships between variables. This feature can be very helpful in various scenarios, such as diagnostics or cases where data drift might occur.
It, however, comes at the cost of stronger modeling assumptions than other statistical methods and predictive machine learning approaches.
Table 1: Comparison between predictive machine learning and causal machine learning
If you are looking to build machine learning models that don't just predict patterns but understand the underlying causes, Digital Sense may be the company you are looking for to collaborate with. Check out our Machine Learning services or get in touch with our business developer, Andrea Mikhaloff – andrea.mikhaloff@digitalsense.ai – to start your project.
References
[1] Correlation vs Causation: Learn the Difference - https://amplitude.com/blog/causation-correlation
[2] Causal Machine Learning: A Survey and Open Problems - https://arxiv.org/abs/2206.15475
[3] Generative Interventions for Causal Learning - https://arxiv.org/abs/2012.12265



.jpg)