
This post is part of a series where Digital Sense presents key scientific contributions from our team members or collaborators, translating advanced research into insights for a broader technical audience.
In this edition, we explore a new video inpainting method developed by our colleagues Nicolas Cherel, Andrés Almansa, Yann Gousseau, and Alasdair Newson: “Infusion: Internal Diffusion for Inpainting of Dynamic Textures and Complex Motion”.
The work proposes a new method for video inpainting (reconstructing missing/deleted parts of videos), particularly in cases involving complex motion patterns and dynamic textures.

What is video inpainting?
Video inpainting refers to the process of automatically reconstructing missing or occluded regions in a video sequence. Imagine removing an object from a movie scene—a microphone boom, a passing pedestrian, or a watermark—and replacing it with realistic background content, without leaving any noticeable trace.
Traditionally, this task has been solved in the following main ways:
- Patch-based methods: Copying and pasting spatiotemporal patches from elsewhere in the video to fill the missing region.
- Optical-flow methods: Another class of approaches is based on optical flow. Indeed, in many situations, especially when the occluded region is observed at some point in time in the video, optical flow gives very useful information. While effective for static backgrounds, they generally struggle with dynamic textures like waves, smoke, or crowds.
- Deep learning methods: Training neural networks to predict what the missing content should look like. These approaches can be powerful but often require huge datasets and still face difficulties with long-term temporal consistency.
The Infusion method introduces another approach: combining the internal statistics of a video (self-similarity across frames) with a diffusion-based generative model. Rather than relying on external data or training sets, Infusion learns directly from the video itself, making it particularly robust when handling highly specific or rare patterns of motion.
Why does it matter?
The importance of video inpainting extends across industries, but not all applications demand the same level of fidelity. In some contexts, the priority is visual plausibility rather than absolute factual accuracy. In these domains, introducing hallucinated but perceptually convincing content is acceptable—and even desirable—because the goal is to produce visually seamless results for human observers rather than scientifically precise reconstructions.
Some applications where plausible hallucinated content is acceptable or desirable include:
- Film and media production: Inpainting is routinely used in post-production to remove microphones, wires, logos, or unwanted passersby. As long as the reconstruction is visually convincing, it doesn’t matter if the filled regions are statistically accurate to reality.
- Advertising and marketing: Brands often need to re-edit promotional videos by erasing old products, replacing signage, or modifying environments. A plausible illusion is sufficient for storytelling and aesthetic purposes.
- Video restoration and archiving: For restoring damaged or incomplete film reels, the priority can be aesthetic continuity and preserving audience experience. Hallucinated content, if consistent with the application’s goals, enhances usability of historical footage.
From a broader perspective, this research addresses three major challenges in AI-based video processing:
- Dynamic textures: Unlike rigid objects, textures such as water, fire, smoke, or foliage exhibit stochastic but structured motion. Accurately reconstructing these requires models that capture their statistical distribution, not just their appearance.
- Complex motion: Human and animal movements, crowds, or camera pans involve long-range dependencies across frames. Standard methods often introduce artifacts or temporal inconsistencies in these settings.
- Data efficiency: Most state-of-the-art methods rely on massive datasets. Infusion, by contrast, is self-supervised—it trains only on the input video, adapting directly to its unique statistics.
This makes Infusion a scalable, generalizable, and practical solution for real-world applications where annotated training data is scarce or unavailable.
The Infusion Method
The Infusion method is built on the foundation of diffusion probabilistic models (DDPMs), a generative framework that has recently proven extremely powerful in tasks like image synthesis. At a high level, these models learn to progressively remove noise from a random signal until it becomes a structured output—in this case, a video with missing regions filled convincingly.
Infusion is not only innovative because its use of diffusion for inpainting but also for its adaptation of the training process and network architecture to video. Here, temporal coherence is essential and computational costs are prohibitive if not carefully addressed.
Background: Diffusion for inpainting
Diffusion models operate through two complementary processes:
- Forward process: progressively corrupting the video data by adding noise in multiple steps.
- Reverse process: a neural network learns to undo this corruption step by step, reconstructing the clean video conditioned on the known (unmasked) regions.
For inpainting, the model must learn the conditional distribution of a video given the visible parts. This requires explicitly incorporating the observed pixels and the inpainting mask into the diffusion process. In Infusion, this conditioning is implemented via concatenation of the known region and mask into the input layers of the network.
Architecture: Lightweight 3D U-Net
A major contribution of Infusion is its lightweight 3D U-Net architecture:
- 3D convolutions are used, instead of 2D convolutions, to preserve temporal information across frames, ensuring that the filled regions remain consistent over time.
- The network is intentionally compact, with 16 convolutional layers distributed over four levels, using only 32 channels per layer. This design results in roughly 500,000 parameters, in contrast to the hundreds of millions or even billions of parameters in typical video diffusion models.
- Downsampling is applied only in the spatial dimensions, not the temporal one, to avoid losing temporal coherence.
- Skip connections and nearest-neighbor upsampling ensure that fine spatial details are preserved.
This architecture strikes a balance between capacity and efficiency, allowing training and inference to remain feasible on a single GPU within hours rather than days.
Internal learning: Training on a single video
A key innovation of Infusion is its ability to train exclusively on the input video itself. This paradigm is known as internal learning, and it leverages the natural redundancy of video data. Indeed as videos are highly auto-similar, most frames share large amounts of content, with only gradual motion changes.
This idea has roots in earlier work on patch-based inpainting and Deep Image Prior approaches, where a network learns structure directly from the target sample rather than from an external dataset.
Training procedure
Unlike traditional deep learning approaches that rely on large external datasets, Infusion employs an internal learning strategy.
Indeed, the diffusion model is trained by creating random training masks in the visible part of the video (as the green mask in Figure 2) that the model should learn to restore. At inference the model is applied on the test mask (red mask in Figure 2) that contains the object we wanted to remove all along.
Note that this procedure leverages the auto-similarity hypothesis of video data—most visual structures and textures reappear across frames, even under motion. Moreover, what would typically be considered “overfitting” in machine learning is in fact desirable here: the model learns the unique characteristics of the video to reconstruct its missing regions. This internal training avoids the need for pre-training on massive corpora, while still producing reconstructions that are both temporally stable and perceptually convincing.
Interval training: A novel contribution
An important innovation introduced in this work is interval training, a divide-and-conquer strategy for diffusion models:
- In standard diffusion, the network must handle all timesteps (from high-noise to low-noise states) simultaneously. This forces the model to be extremely large and versatile.
- Infusion instead divides the timesteps into intervals. The network trains on one interval at a time, specializing in handling a narrower range of noise levels.
- After training on one interval, inference is performed for that range before moving to the next interval. This process repeats until the video is fully reconstructed.

Advantages of interval training:
- Allows a small network (500k parameters) to achieve results competitive with much larger models.
- Eliminates the need for complex loss weighting schemes typically required in diffusion training.
- Significantly improves reproduction of fine details and textures, as shown in comparative experiments.
In practice, the paper shows that dividing 1,000 diffusion timesteps into intervals of 50 strikes the best balance between efficiency and reconstruction quality.
Training and inference details
- Training setup: Infusion resizes videos to 432×240 and trains on 20 consecutive frames at a time. Training takes 3–15 hours on a single NVIDIA V100 GPU, depending on the kind of content in the video. Inference takes around 5 seconds per frame.
- Loss function: An L2 reconstruction loss is applied only in the masked regions, ensuring the model focuses learning on missing content.
This design enables Infusion to be practical for applied scenarios, unlike generic diffusion models that can require prohibitive compute resources.
Key features include:
- Patch-based self-conditioning: The model uses existing video content as priors, ensuring consistency with the observed motion.
- Temporal coherence: Unlike frame-by-frame methods, Infusion operates across time, reducing flickering artifacts and preserving motion trajectories.
- Generalization to complex motion: The method succeeds where traditional patch-based techniques fail—such as in reconstructing breaking waves, flowing rivers, or groups of people.
Experimental Results
The authors validate Infusion across multiple benchmarks of video inpainting.
Quantitative metrics:
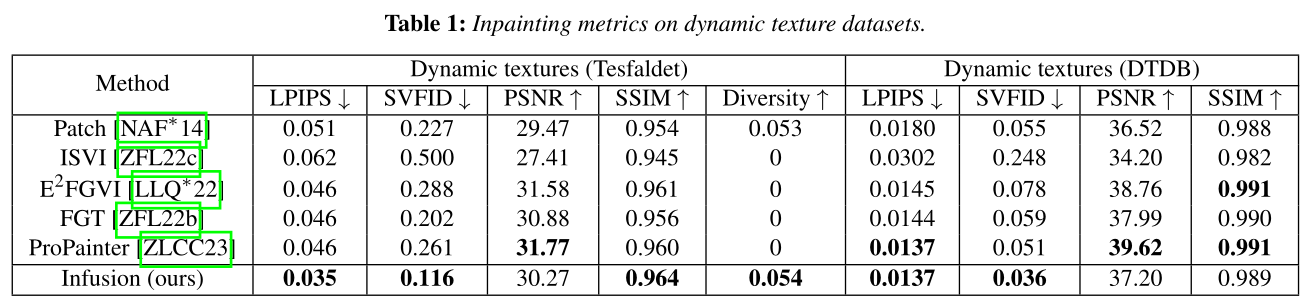
Infusion outperforms state-of-the-art patch-based and learning-based methods on SVFID (Single Video FID), SSIM (Structural Similarity Index) and LPIPS.
Qualitative performance:

- In dynamic textures, competing methods often produce visible seams, ghosting, or frozen textures.
- Infusion generates realistic, temporally stable reconstructions with natural dynamics.
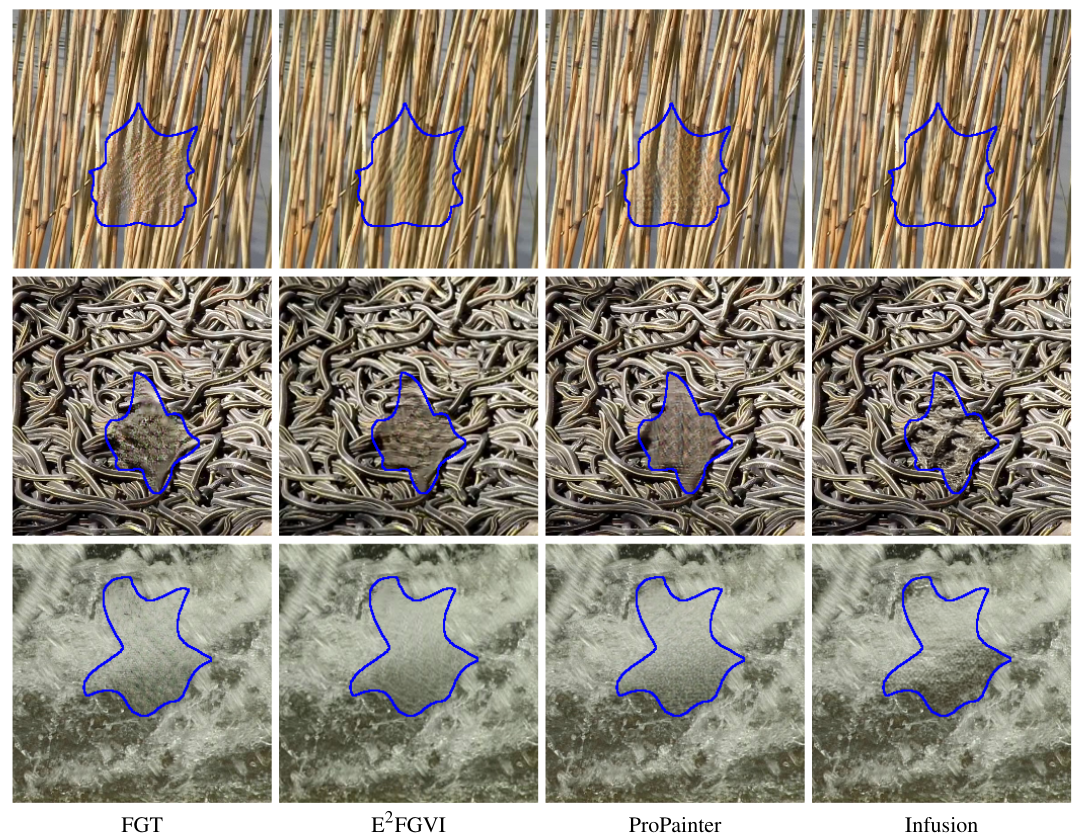
We encourage you to see further results and videos on the project’s page.
Limitations and Failure Cases
While Infusion shows clear advantages, the authors also acknowledge certain limitations:
- Static backgrounds: the limited receptive field of the convolutional architecture in the temporal dimension can impair Infusion’s capability to reproduce still backgrounds for large periods of time.
- “Single-use” models: each model is “single-use”, in the sense that it is adapted to a single video. This makes sense in the case of video inpainting, and greatly reduces network size and training time, but means that the model cannot be re-used. The optical flow is more generalizable from one video to the next but is limiting for elements such as dynamic textures.
- Introducing external content: Infusion relies on the content of the video to inpaint may have difficulty introducing completely unseen content in the reconstruction.
Conclusion
The work of Nicolas Cherel, Andrés Almansa, Yann Gousseau, and Alasdair Newson exemplifies how research in computer vision translates into tools with broad industrial impact. By addressing the long-standing challenge of video inpainting under dynamic textures and complex motion, Infusion opens the way to more robust, scalable, and general-purpose solutions for industries relying on high-quality video data.
Infusion introduces three major innovations to the field of video inpainting:
- A lightweight 3D U-Net with only 500k parameters, preserving temporal coherence without excessive computational cost.
- An internal learning strategy that leverages the self-similarity of video data, eliminating the need for large external datasets.
- Interval training, a novel scheme that enables efficient training across diffusion timesteps, improving quality while reducing resource demands.
Together, these advances allow Infusion to achieve state-of-the-art results on dynamic textures and complex motion, a domain where traditional methods struggle.
At Digital Sense, we recognize that such innovations are not just academic achievements—they form the foundation for applied AI solutions, so if you'd like to get to know more about our solutions in computer vision, don't hesitate to get in touch.
Contact Us
As a company built for innovation with a team of PhDs and experienced engineers, Digital Sense is aware and involved in the latest AI research.
If your organization is looking for computer vision, data science, or machine learning experts, we invite you to explore our capabilities. Visit www.digitalsense.ai or schedule a consultation. You can also check our success stories for examples of past projects.
Reference
Cherel, N., Almansa, A., Gousseau, Y. and Newson, A., 2025, April. Infusion: internal diffusion for inpainting of dynamic textures and complex motion. In Computer Graphics Forum (p. e70070).



.jpg)
