
Introduction
At Digital Sense we have worked on projects that did not quite fit into a cloud-based solution, so we took a step back to rethink the approach. This is where Edge AI came into play for us.
For many of our projects, the default answer to “where should this AI Computer Vision model run?” has been the cloud. But when the input is continuous video, such as security cameras, industrial lines, drones, or traffic intersections, the cloud quickly stops being a one-size-fits-all solution. We realized that, unlike traditional data pipelines, video-based AI systems produce continuous, high-bandwidth streams that introduce a completely different set of scalability constraints.
To put some of these constraints into perspective, there are a few that consistently stand out in real-world projects and that we constantly encounter across different projects. One of the most important one is latency, where Edge AI tends to make a significant difference.
In applications that need real-time actions like collision avoidance or automated control, delays of a few decimals of a second can be critical and might turn an otherwise accurate model ineffective. If captured frames need to travel to the cloud to be processed and then return with a decision, the feedback loop breaks.
Moreover, the cost of ingesting and retrieving large volumes of video data from the cloud can quickly get out of control and as the number of cameras and deployment sites grows, so do egress fees, storage costs, and the compute required for always-on inference. What one started as a manageable pilot can rapidly turn into a budget constraint problem.
What Does Edge AI Mean?
One thing we can say for sure is that Edge AI does not mean abandoning the cloud, it means rethinking where data lives in your system. At its core, Edge AI is about running models directly on edge devices, close to the data source, so inference and decision making happen locally instead of relying on round trips to a remote data center.
Edge and cloud: complementary, not rivals
Edge AI and cloud computing are complementary parts of AI architecture, they are not competing choices. Some workloads naturally belong at the edge, especially low latency, safety critical decisions, deployments with limited bandwidth, or privacy sensitive environments and others, such as large scale batch processing or model training are still almost exclusively suited for the cloud.
The real question is not “edge or cloud?”, but rather: Which parts of the pipeline belong in each place?
Role of Specialized Hardware: Qualcomm QCS8550
Running a model is not the only challenge, and if that were the case, a general purpose computer like the ones we have at home could handle some low intensity edge-computing. The difference between general purpose computer and hardware specifically designed for on‑device AI workloads, such as Qualcomm‑based platforms, is huge here.
From generic CPUs to purpose‑built AI
As solution developers, we need devices that can run continuously, tolerate temperature swings, and still deliver predictable performance. This is where the Qualcomm QCS8550 makes all the difference in the world. It is designed exactly for embedded, industrial, and edge‑video deployments. It achieves low power consumption, around 16 watts, as specified by the provider, while still delivering low inference latency, making it the perfect fit for real‑time computer vision workloads.
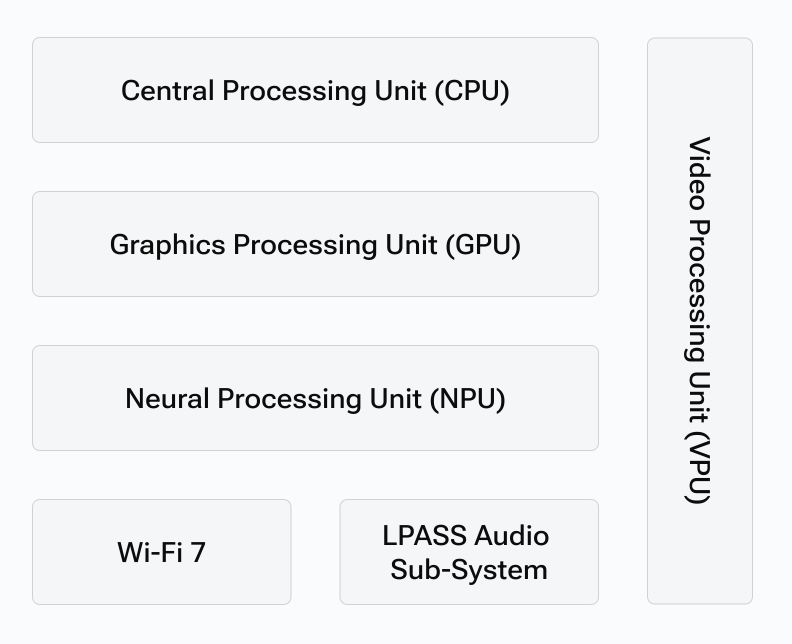
The QCS8550 integrates:
- Multi‑core Kryo CPU for general purpose compute tasks and orchestration.
- Integrated Adreno GPU to accelerate unsupported neural network layers that need GPU fallback.
- Dual eNPU V3, HVX, and HMX optimized specifically for inference workloads
Although TOPS alone do not determine real‑world performance as peak theoretical throughput is just one data point, it remains a useful reference metric when comparing platforms. For the QCS8550, Qualcomm declares the hardware is able to deliver 48 TOPS (INT8).
Check out Qualcomm’s official web to learn more about QCS8550 specifications.
Real-World Use Cases of Computer Vision on the Edge
Now that we have established that Edge AI is a compelling alternative in scenarios where cloud computing becomes impractical it is worth grounding the discussion in real-world applications. At Digital Sense, we have identified several cases where on device computer vision is a better fit as a solution as it improves system design and aligns naturally with the constraints of the environment.
Limited connectivity environments: ships, aircraft, and remote sites
In these environments connectivity is often intermittent or entirely absent. Meaning that sending continuous high bitrate video streams to the cloud is neither feasible nor economical so it becomes the perfect example where edge AI turns this constraint into an opportunity: instead of streaming everything, the system performs on‑device video processing keeping only the important information.
- Process raw or high‑resolution videos to detect anomalies, track objects, or verify safety checks in real time.
- Focus on what matters by storing only important events. Non‑critical footage can be discarded or compressed.
- When a reliable connection becomes available such as a ship returning to port or an aircraft landing only selected data is uploaded on demand for further analysis.
This makes it possible to be more effective, tunrin the edge device into a self-sufficient “always-on” node that leans on the cloud only when necessary.
Industrial environments: real‑time control and autonomy
In industrial settings, computer vision often associated with immediate control actions, such as triggering alarms or stopping production lines. These systems, most of the times, rely on high‑quality information, often with minimal compression, because details and timing matter more than bandwidth saving. Here’s where sending data to the cloud for every decision poses difficulties:
- High latency: If the system needs to wait for frames to travel to the cloud, be processed, and return a control signal, it can break the tight feedback loops required by safety or process control systems.
- Dependency on network availability: Even short outages can disrupt control loops, halt production and/or create unsafe conditions. Plus, in an industrial plant, minutes of downtime can translate into significant financial loss for our clients.
- Operational risk: If network failures can bring down critical systems, the architecture itself becomes a single point of failure.
Case Study: A Digital Sense deployment
The New York City Department of Transportation (NYC DOT) needed to detect the presence and condition of speed limit signs, as well as identify streetlights that were off or malfunctioning. We had no georeferenced database of sign locations or any historical records of damaged or missing signs so we had no data to start with. When an issue was detected, the system had to provide a georeferenced image with precise location and timestamp as evidence to enable downstream teams to validate and act on the finding.
Requirements and scalability
The system was expected to support near real‑time updates, with data available for ingestion and reporting within a single day. Large processing backlogs were not acceptable, as they would make it impossible to keep the map or asset inventory “fresh”. At first glance, a small‑scale cloud based deployment with one or two vehicles could work, but when scaled to 100 vehicles operating for 8 hours per day, the volume of continuous video generated would quickly demand us heavy, centralized cloud infrastructure with significant implications for cost and complexity.
A purely cloud approach faced several hard limitations, to mention a couple:
- High costs for transmitting high resolution dashcam footage over the 4G mobile network.
- High costs for developing and managing complex system able to support large volumes of concurrent high bitrate video streams
Edge‑based architecture in practice
To address these constraints, we found that a posible solution was to shifted intelligence from the cloud to the vehicle. Each QCS8550 based device performed an object detection and classification models locally, running on the Qualcomm platform’s dedicated AI cores. Only relevant detections in this case signs and malfunctioning streetlights were sent to the cloud, along with their geotagged metadata and supporting image evidence. All other frames, which carried no actionable insight, were discarded by the device and not sent to the cloud. This means that while all frames are captured, only some of these frames are relevant to the solution. Within that subset, the system focuses on:
- Sign detections and classification.
- Light outage detection (e.g., “streetlight off at location X”).
- Relevant metadata that in this case is timestamp, GPS, confidence score and thumbnails.
Why high resolution matters for some video‑based CV
High resolution was necessary in this particular challenge for text detection on small or distant signs. In high‑motion video streams such as dashcam footage, temporal redundancy between frames is significantly reduced as the image is in constant change. This makes video encoders need more bits per frame to preserve image quality, leading to a substantial rise in bitrate if you aim to maintain some image features recognizable and avoid large artifacts.
Under these conditions, transmitting all frames to the cloud quickly becomes prohibitively expensive which is especially true if using mobile internet plans where usually providers offer 5 GB of high‑priority data per month on lower tiers and around 100 GB on higher tiers before throttling.
Deployment procedure
For anyone having a similar challenge that is looking to replicate a system like this, the following outlines the end‑to‑end process we used to design and deploy it.

Data collection
The first step is installing a Qualcomm QCS8550‑based device in the vehicle and using it as an onboard computer just for data capture. This device operates in a high‑volume raw data‑throughput mode, enabling large‑scale video collection from multiple cameras. This is done while simultaneously logging GPS, timestamps, and other sensor data. By combining these elements, we ensure that the system can record representative footage under real‑world driving conditions.

Processing: labeling, training, and model preparation
Once footage is captured, the next phase is data labeling. Collected clips are annotated to build a representative training dataset. This labeled dataset is then used to train a YOLO based object detection model, chosen for its strong performance in real‑time scenarios and its compatibility with the Snapdragon Neural Processing Engine (SNPE) SDK.

The trained model is exported from its original framework (e.g., PyTorch or TensorFlow) into TFLITE, then converted to DLC, Qualcomm’s proprietary format for NPU‑optimized execution. That is followed by quantization from FP32 to INT8, which enables far more efficient execution on the device’s NPU. While quantization typically involves a small trade‑off between accuracy and performance, it is essential for achieving real‑time inference at the edge. A representative set of in‑field images is used during quantization to preserve performance on the specific conditions encountered in deployment. Qualcomm’s SNPE SDK provides the tools needed for both model conversion and quantization.
For example, converting a TFLite model into SNPE DLC format can be done with
```bash
snpe-tflite-to-dlc \
--input_network MODEL.tflite \
--output_path MODEL.dlc \
```
For models that are not single-input single-output (SISO), all input tensor names and dimensions must be provided explicitly, along with the output node names to be preserved in the converted DLC.
Once the model is converted, it is fundamental to quantize the model. For this step you will need to have a previously converted set of raw format images and a input list `.txt` file listing the paths to each image. It is crucial to use a list of sample images that reflect real deployment conditions.
```bash
snpe-dlc-quantize \
--input_dlc MODEL.dlc \
--output_dlc MODEL_INT8.dlc
--input_list QUANTIZATION_LIST.txt
```
Inference pipeline and system layout
The deployed pipeline is intentionally simple and can be summarized by the following block diagram:
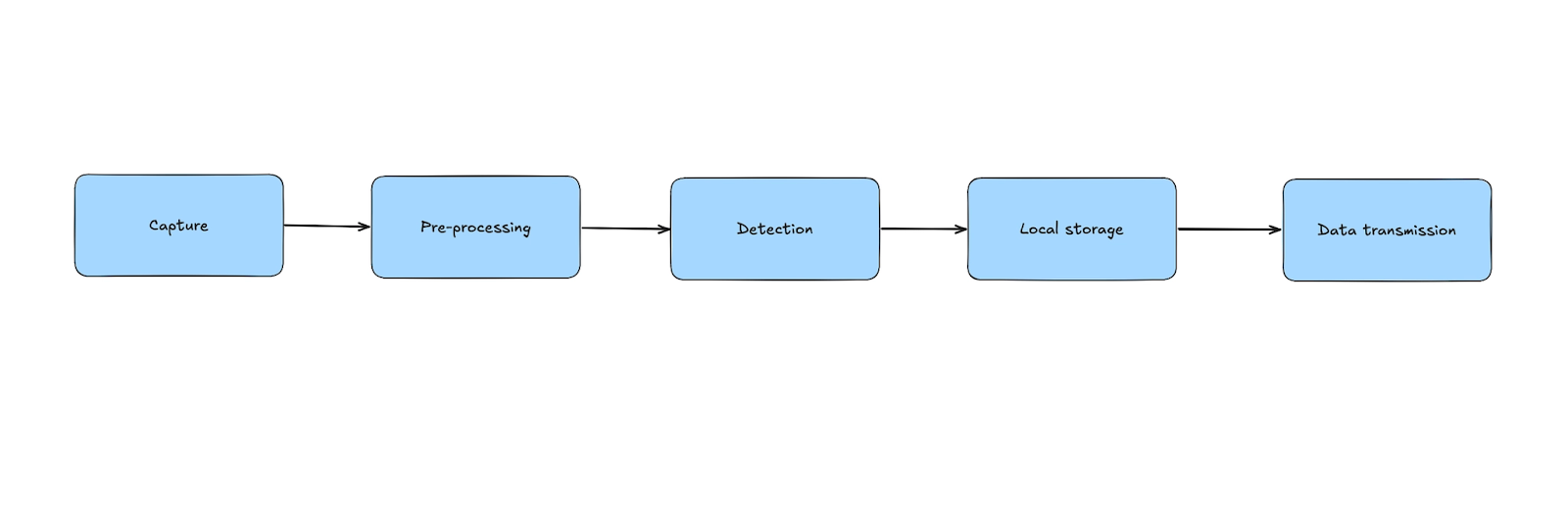
At a high level, frames are captured from the camera and , pre-processed to match the model’s input requirements, and passed to the inference stage. The resulting detections are then post-processed and either stored locally or selectively transmitted to the cloud. Some preprocessing operations such as image resizing or color format conversion can be offloaded to dedicated hardware blocks when available and in this way reduce CPU utilization.
In practice, the most complex stage of the pipeline is the inference step. Integrating with the SNPE runtime through its C++ API requires careful handling of buffer formats, size and allocation. Qualcomm’s official documentation and sample applications are highly recommended, as they help avoid common integration pitfalls.
To get the most out of our QCS8550 platform, we designed the pipeline as a multi-threaded system. This allows frame capture, preprocessing stage, inference and post-processing to all run as parallel tasks which overall boosts the whole system throughput.
Conclusion
To round things up, at Digital Sense we are convinced that Edge AI is a natural evolution towards smarter cities, vehicles, industrial systems and much more. Even though the technology still faces challenges, particularly in terms of the ecosystem and cross-framework compatibility, its potential is undeniable.
Our talented team of engineers has welcomed these challenges, delivering complex end-to-end solutions in which Edge AI has been a key building block, extending our toolbelt of development capabilities.
To learn more about the projects mentioned, I invite you to read our press release and do not hesitate to contact us for your next Computer Vision and Edge project. If you have any doubts, we can answer all your questions.



