As Large Language Models (LLMs) offer powerful general capabilities, they can also lack individual enterprises' specific, proprietary context. Two primary methodologies have emerged to adapt LLMs for companies' use: Retrieval-Augmented Generation (RAG) and Fine-Tuning.
In this article, we’ll compare them, hoping to help technical leaders select the right approach. It details fine-tuning, and particularly efficient methods like Parameter-Efficient Fine-Tuning (PEFT) and Low-Rank Adaptation (LoRA), which specialize a model's behavior by adjusting particular parameters to teach new skills or styles. In contrast, RAG enhances LLMs by connecting them to external knowledge bases at inference time, retrieving relevant, up-to-date information to ground responses in factual data.
With a side-by-side comparison, we outline ideal use cases for each method and explore how hybrid approaches (like Retrieval-Augmented Fine-Tuning) can combine both strengths for optimal performance.
Introduction to RAG and Fine-Tuning
Adapting a foundational LLM to a company's domain is not a one-size-fits-all problem. This adaptation comes in two major flavours: injecting knowledge at inference time with RAG or embedding domain knowledge into the model’s parameters by fine-tuning. The choice of which approach to follow has significant implications.
What Is Fine-Tuning?
Fine-tuning is the process of further training a pre-trained model on a smaller, domain-specific dataset. This procedure adjusts the model's internal weights, or parameters, to specialize its behavior and knowledge for a particular task. A model needs to be open-sourced for it to be further trained; therefore, adapting proprietary models such as ChatGPT or Gemini with this technique is impossible. Even if open-sourced, LLMs' size varies from 100 million (BERT) parameters to 100 billion parameters (GPT-OSS). So while effective, traditional full fine-tuning is computationally expensive, requiring significant resources to update billions of parameters and hundreds to thousands of hours of GPU computing.
Parameter-efficient fine-tuning and LORA
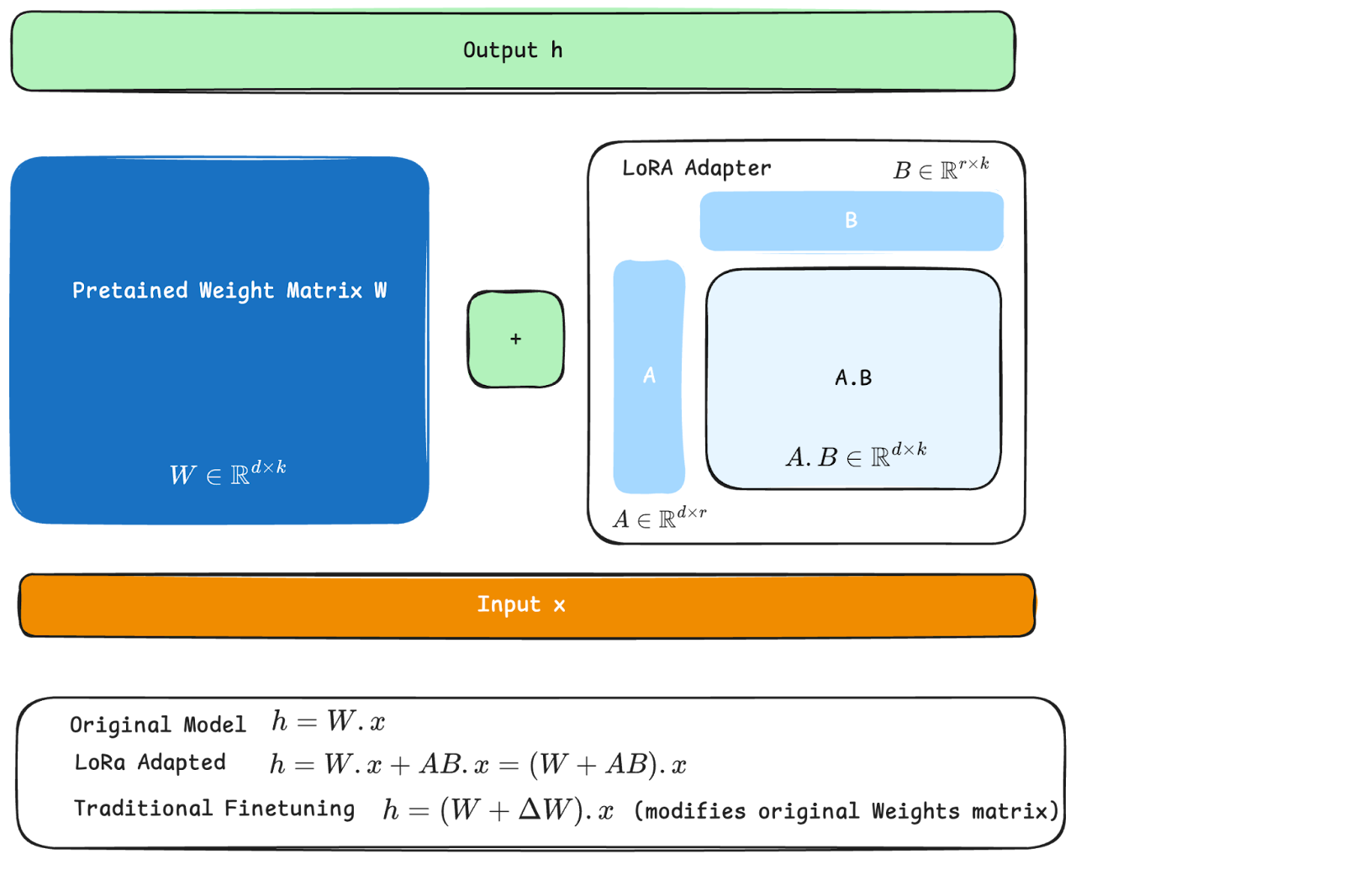
Given the computational restrictions of fully adapting LLM parameters, more efficient methods need to be used, these are called Parameter-Efficient Fine-Tuning (PEFT) methods. PEFT techniques were originally introduced in [1] and only modify a small subset of the model's weights, drastically reducing computational and storage costs while achieving performance comparable to full fine-tuning. Among the most prominent PEFT techniques is Low-Rank Adaptation (LoRA) [2]. LoRA operates on the principle that the change in model weights during adaptation has a low "intrinsic rank." It freezes the original model weights and injects trainable, low-rank matrices called adapters into the layers of the transformer architecture [3]. During training, only these small adapters are updated, representing a tiny fraction of the total parameter count—often less than 1%. This makes training faster, and the resulting LoRA adapters are typically only a few megabytes in size, making it feasible to have many task-specific adapters for a single base model.
Conceptually, LoRA exploits the idea that the core operations within attention layers in transformers are inner products or linear operations. The following diagram graphically explains how LoRA modifies weight matrices in transformers. LoRA simplifies the process of adapting original weights (as in traditional fine-tuning) by adding a factorized matrix (A.B in the diagram) of adaptation weights.
What Is RAG (Retrieval-Augmented Generation)?
Retrieval-Augmented Generation (RAG) is a powerful alternative that enhances LLM responses by providing them with external, up-to-date information at inference time. It basically expands the original prompt with relevant context that helps answer the target question. Instead of embedding knowledge directly into the model's parameters it connects the LLM to a company's proprietary knowledge base.
The RAG architecture consists of two main stages: Retrieval and Generation. For these steps to work we need a previous step which consists of indexing our knowledge base.
- Knowledge Base Indexing: This process involves converting the documents in a knowledge base into numerical representations (embeddings) using Embedding Models. These models are closely related to LLM models but are specifically trained to transform human text into vectors rather than generating text. Their goal is to map texts with similar semantic meaning to vectors that are close in distance within the embedding space. Indexing the knowledge base includes dividing documents into semantically coherent structures (e.g., paragraphs) and converting these chunks into embeddings. These vectors are then stored in a vector database, such as ChromaDB or Qdrant, which is optimized for computing vector distances and queries.
- Retrieval: When a user submits a question, the system first retrieves relevant information from the knowledge source. It transforms the user query using the embedding model and performs a similarity search to find the document chunks most relevant to the query's vector. These chunks are ranked by their similarity to the user's question.
- Generation: The text information associated to the retrieved embedding is then concatenated with the original user prompt and fed to the LLM as additional context. The LLM uses this context to generate a response that is grounded in the provided data, significantly improving factual accuracy and reducing the likelihood of "hallucinations"—plausible but incorrect statements.
The following diagram illustrates the Retrieval and Generation process graphically.

Fine-Tuning vs. RAG: A Side-by-Side Comparison
The decision to use fine-tuning or RAG depends on the specific objectives of the AI application. Each method offers distinct advantages and disadvantages. Therefore, we provide some scenarios where is most convenient chose each alternative
When to Choose Fine-Tuning
Fine-tuning is a sensible choice when the goal is to alter the behavior of the LLM. It excels in scenarios such as:
- Adopting a specific tone or style: If you need the LLM to communicate in a particular brand voice or conform to a strict output format (e.g., generating code, specific JSON structures, particular formal or legal styles), further training the model on examples of that style is highly effective.
- Learning implicit domain knowledge: For specialized fields with unique jargon, nuances, and reasoning patterns (e.g., legal analysis, clinical diagnostics), additional training helps the model internalize these complex relationships.
- Teaching the model new skills: When the task involves learning a new capability that isn't easily captured in a document, such as summarizing text in a highly specific way or translating between niche languages, fine-tuning is necessary.
- Correct inaccuracies or Hallucinations: In some cases hallucinations and inaccuracies can be corrected by the means of prompt engineering and additional context. In these cases re-optimizing the model with a few (few hundred) of correct examples can drastically improve the accuracy of the model.
When to Choose RAG
RAG is the preferred method when the primary requirement is providing the LLM with access to a body of new factual information. It is ideal for:
- Knowledge-intensive applications: For building chatbots, Q&A systems, or internal knowledge search tools that need to provide answers based on a specific corpus of documents (e.g., company policies, technical manuals, product catalogs).
- Applications requiring up-to-date information: If the knowledge base is dynamic and changes frequently (e.g., news articles, financial reports, inventory status), retrieval and generation allows for real-time updates without the need for constant model retraining.
- Reducing factual inaccuracies: When factual precision is paramount, retrieving appropriate knowledge grounds the model in verifiable data, providing users with trustworthy and citable answers.
Can You Combine RAG and Fine-Tuning?
These techniques are not mutually exclusive; they can be combined to create a highly sophisticated and powerful system. One such hybrid approach which leverages the strengths of both methodologies is Retrieval-Augmented Fine-Tuning (RAFT) [4].
In this paradigm, an LLM can be fine-tuned first to better understand the nuances and terminology of a specific domain. For example, a model could be fine-tuned on a corpus of financial documents to learn the language and common reasoning patterns of financial analysts. This specialized model is then integrated into a RAG system, where it can query a vector database of real-time market reports. The fine-tuning helps the model to ask better questions (i.e., generate more effective query embeddings) and to synthesize the retrieved financial data into a high-quality, expert-level response, discarding irrelevant documents if they are retrieved. This layered approach provides specialized capability and access to factual knowledge.
The Future of LLM Adaptation
The field of LLM adaptation is evolving rapidly. We are seeing the development of more advanced RAG techniques that involve sophisticated query transformations and multi-step or multi-level retrieval processes. Simultaneously, a plethora of PEFT methods besides LoRA have been emerging that offer even greater efficiency. Besides these adaptations are becoming multimodal, in the sense that LLMs can now interact with images, extract information from them and retrieve relevant graphs and diagrams from knowledge bases. The future of enterprise-grade AI will likely be dominated by these hybrid systems that intelligently combine the behavioral adaptations of fine-tuning with the factual grounding of RAG that leverage multimodal data sources, creating models that are both expert in their domain and consistently accurate.
How Can Digital Sense Help You Implement RAG and Fine-Tuning?
Choosing between RAG, fine-tuning, or a hybrid approach is a critical strategic decision that depends entirely on your specific business needs, data, and objectives. Fine-tuning with methods like PEFT is ideal for embedding new skills and styles into Large Language Models, while RAG excels at providing them with access to vast and dynamic knowledge bases through the use of embedding models and vector stores.
Navigating this requires deep expertise. With over a decade of experience in machine learning and data science, our team knows how to design and implement sophisticated LLM solutions according to your needs. We have delivered multiple successful projects making language models work with the company’s data, such as legal documents, product catalogs, or technical manuals for industrial processes.
Whether you require advanced consultancy to determine the best path forward or end-to-end development of a custom RAG or fine-tuning solution, Digital Sense has the scientific rigor and engineering excellence to deliver.
Explore our NLP and LLM development services to see how we can help you harness the power of your company's data.



.jpg)