
If you're considering Databricks, you know that managing data at scale is one of today's most significant engineering challenges. You need a platform that combines high-throughput ingestion with the governance and reproducibility required for production-grade machine learning (ML). Databricks offers this through its integrated Lakehouse architecture.
This technical guide is designed to get you and your team up and running fast. Authored by the engineering team at Digital Sense, it's built on insights from real-world projects.
Inside, you'll find:
- A clear breakdown of Databricks' core features.
- Step-by-step instructions to start with the Free Edition.
- A hands-on walkthrough using a real-world public dataset.
- A checklist for a responsible, production-ready rollout.
What is Databricks and Why Should You Care About It?
Databricks is an integrated analytics platform built on Apache Spark and extended with native components for transactional storage, high-performance query execution, ML lifecycle management, and collaboration. Its Lakehouse model bridges the flexibility of object-store data lakes and the transactional guarantees of data warehouses; this hybrid approach supports both large‑scale analytics and structured workloads in a single platform.
Core components and technical rationale
- Delta Lake: Offers ACID transactions, schema enforcement, and time travel on top of object storage. For production pipelines, Delta Lake is the foundation for consistency and reliable incremental processing.
- Photon and query engine optimizations: Databricks provides vectorized and native execution engines to accelerate SQL and analytical workloads, improving throughput for analytical queries with lower CPU time per query.
- MLflow: An open framework integrated into Databricks for experiment tracking, model packaging, and model registry, enabling reproducible ML research and controlled model deployment to production.
- Collaboration tooling: Managed notebooks, git repos, and role‑based sharing accelerate team productivity and traceability for data science work.
Why the platform matters for engineering leaders
- Unified execution: Data engineering, analytics, and ML can share a single storage layer and toolchain, reducing data movement and the operational burden of coordinating multiple platforms.
- Scalability and cloud portability: Databricks runs on the major cloud providers, and architecture choices can be aligned with cloud‑native cost and security requirements.
- Productivity gains that scale: Standardized tooling and an integrated ML lifecycle can reduce the cycle time from data ingestion to model deployment, a critical ROI lever for enterprise AI programs. These capabilities are particularly relevant for organizations scaling beyond isolated prototypes.
Databricks Free Edition: Getting Started Without Breaking the Bank
The Free Edition is intended for evaluation, learning, and light prototyping. For organizations that want a low-friction entry point to explore Databricks concepts and prototype workflows, it provides essential capabilities while intentionally limiting production features.
What the Free Edition provides (technical summary)
- Serverless compute for notebooks, SQL, and simple jobs (managed, no cluster configuration required).
- Delta Lake support: create and query Delta tables for ACID‑like behavior within the managed workspace.
- Notebook environment: Python and SQL are supported for interactive development, including basic visualizations and a code suggestion assistant.
- Basic ML features: Experiment tracking is available via MLflow; simple model serving endpoints may be present, but with limited capacity.
Significant limitations that affect architectural choices
- No GPU or custom cluster access: The Free Edition is serverless only; it does not permit custom cluster shapes or GPU instances for large model training. If deep learning training or GPU inference is needed, plan to move to a paid tier.
- Resource constraints: The SQL warehouse is small (2X-small cap), has low concurrency for jobs, and has limited pipeline counts; these constraints affect throughput and parallel experimentation.
- Governance and security features are limited: Unity Catalog, SSO/SCIM, fine‑grained identity management, and enterprise audit controls are absent in the Free Edition; these are critical for regulated or multi‑team production systems.
When to evaluate upgrading
The following factors should be considered when deciding when to upgrade:
- Compute needs: frequent long‑running jobs, GPU training, or heavy query volumes.
- Governance & security: enterprise identity federation, fine‑grained access, lineage, and auditability.
- Operational scale: multi‑team collaboration, orchestration, and production model serving with SLAs.
Hands-On Tutorial: Getting Started with a Public Dataset
The following stepwise example demonstrates practical onboarding in the Free Edition using the NYC Taxi Trip Duration dataset (a widely used public dataset for feature engineering and baseline modelling).
Note: The code below is intentionally minimal to show how to start. For production workloads, apply the best practices described later.
Set up your Databricks workspace (quick checklist)
- Sign up for the Free Edition and create a workspace.
- Confirm your workspace has storage attached (managed default storage).
- Create a notebook and choose Python as the default language.
Data ingestion and Delta table creation
Upload the CSV files (train.csv, test.csv)
Catalog → Workspace → Default → Create → Table → Upload train.csv, test.csv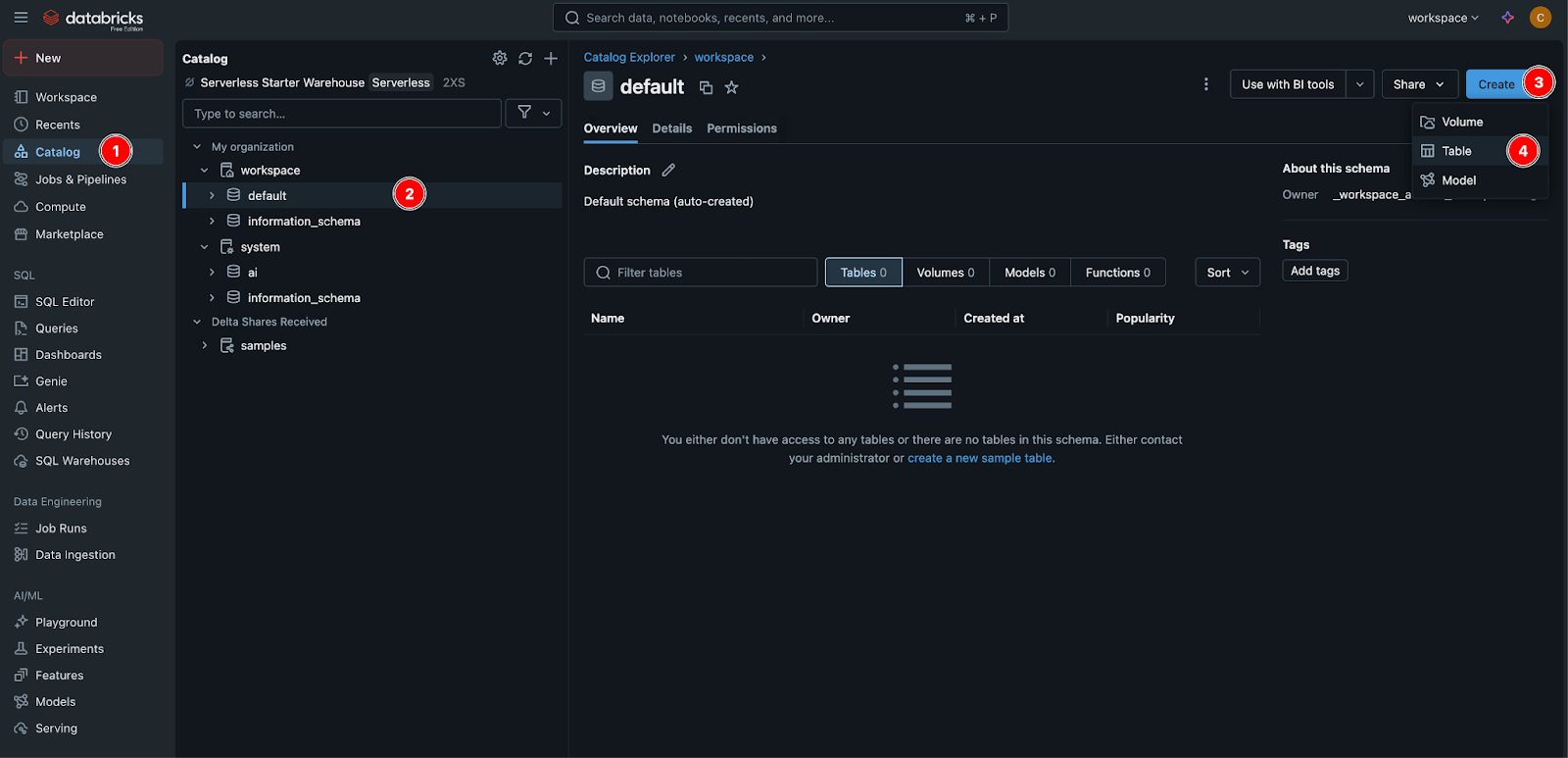
You should have tables like those shown in the image below.
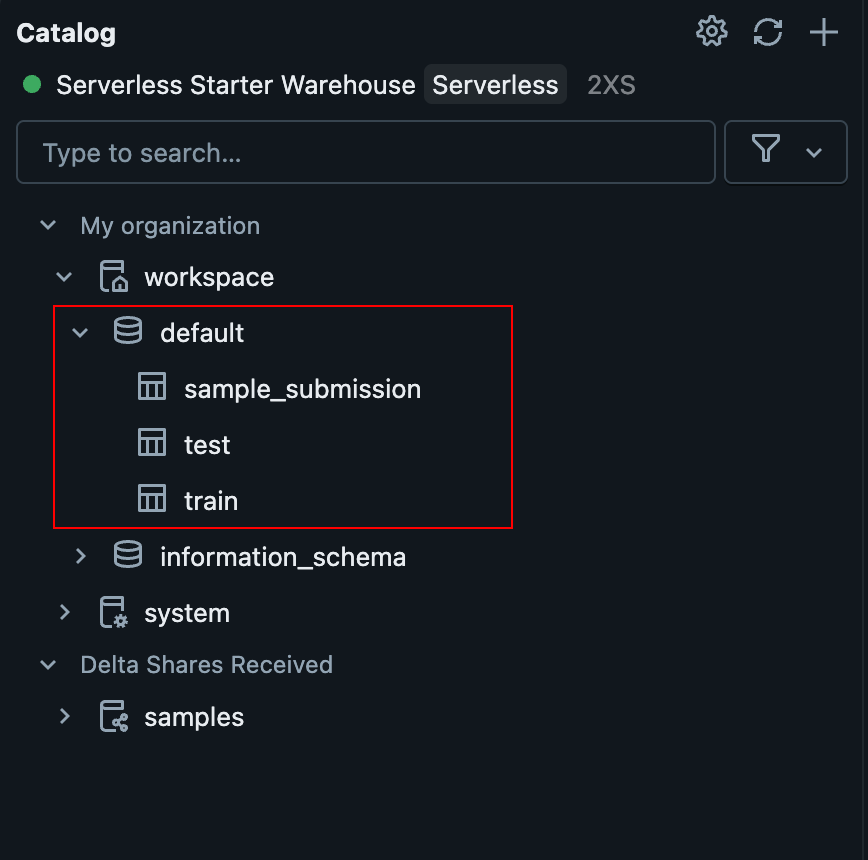
Once registered, you can reference them via Spark SQL or the Spark DataFrame API.
train_df = spark.table("workspace.default.train").dropna()
test_df = spark.table("workspace.default.test").dropna()Performance note: in production, prefer explicit schema definitions and partitioning at write time to reduce schema drift and improve read performance.
Exploratory analysis and plotting (small-sample)
Converting a Spark DataFrame to pandas is practical for small‑sample visualizations but must be avoided on complete datasets.
import matplotlib.pyplot as plt
import seaborn as sns
train_pd = train_df.toPandas()
train_pd["trip_duration_minutes"] = train_pd["trip_duration"] / 60
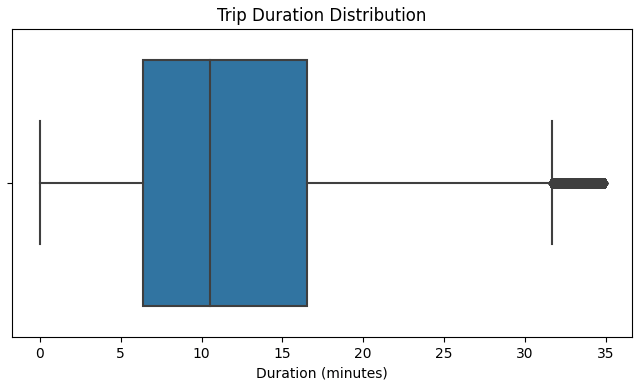
sns.boxplot(data=train_pd, x="trip_duration_minutes")
plt.title("Trip Duration Distribution")
plt.xlabel("Duration (minutes)")
plt.show()
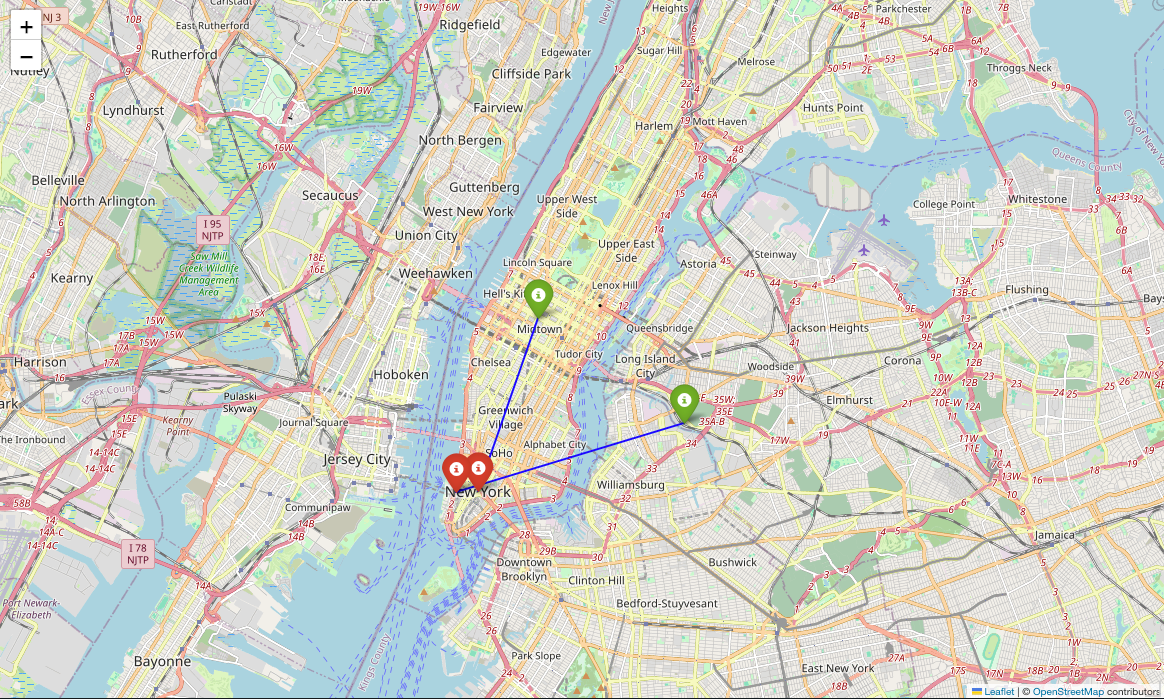
You can also use libraries like geopy and folium to plot pickup and dropoff locations on a map, providing geospatial insights into urban mobility patterns. This can help improve the model's predictive performance.
A simple baseline model (scikit‑learn example)
For lightweight experimentation in the Free Edition, scikit‑learn is convenient:
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LinearRegression
X_train = train_pd[["pickup_longitude", "pickup_latitude", "passenger_count"]]
y_train = train_pd["trip_duration"]
model = LinearRegression()
model.fit(X_train, y_train)Scaling caveat: for large datasets, use Spark MLlib or distributed training on appropriately sized clusters (paid tiers).
Feature engineering and domain signals
In urban mobility datasets, useful feature engineering patterns include:
- Temporal features: hour of day, day of week, holiday flags.
- Geospatial features: Haversine distance between pickup and dropoff, cluster-based location encodings.
- Trip complexity: number of passengers, surge indicators, traffic-level proxies (derived from external APIs or historical speed aggregates).
These engineered features often yield more predictive power than raw coordinates alone.
Tracking experiments and model registry
Use MLflow for consistent experiment tracking, parameter logging, model versioning, and (in paid tiers) controlled model serving. The Free Edition allows MLflow tracking but may limit deployment throughput.
Next Steps and Advanced Learning Paths
Once you have prototyped, the path to production includes architecture hardening, governance, cost control, and operational maturity.
Recommended technical roadmap to production
- Design workspace separation: maintain separate development, staging, and production workspaces or metastore separation to protect production assets.
- Adopt version control: store notebooks and pipelines in Databricks Repos connected to Git and enforce code review workflows.
- Use modular pipelines: adopt dbt or Databricks Workflows/Delta Live Tables to make pipelines idempotent and testable.
- Implement governance: enable Unity Catalog (paid tiers) for unified access control, lineage, and auditing.
Cost and performance controls
- Prefer Job Compute clusters for scheduled jobs, and All‑Purpose clusters only for interactive development. Job Compute is more cost‑efficient for repeatable workloads.
- Use Photon runtimes for SQL‑heavy workloads to reduce CPU hours and lower query latency where supported.
- Implement cluster policies and cost dashboards to attribute and control spend across teams.
Learning resources and certifications
Databricks Academy offers role‑based courses and certifications (Data Engineer, Machine Learning Engineer) that help formalize team capabilities. The Databricks Community and the annual Data + AI Summit are additional venues for technical updates and peer learning.
From Tutorial to Production: How Digital Sense Supports Enterprise Adoption
Digital Sense combines deep data science and machine learning knowledge with practical data-engineering experience to accelerate the adoption of Databricks. Our expertise in data migrations from other data warehouses and infrastructure optimizations in Databricks has achieved:
- Cost reductions in the range of 20 to 40%
- Up to 3× performance gains on complex analytics workloads
At Digital Sense, we specialize in turning advanced AI research into real-world solutions. With over a decade of experience and a team that includes Ph. D.s, Master's holders, and experienced engineers, we help companies make the most of their data. Our approach means going through all of existent information and transforming it into actionable data. You can go from enhancing marketing ROI with perfectly cut customer segmentation, to analyzing predictive outcomes and behaviours.
Recommended next steps
For leaders evaluating Databricks, we recommend the following sequence:
- Pilot in Free Edition (short exploratory project using a public dataset to validate tooling and team workflows).
- Define target production SLAs and governance requirements.
- Plan a staged upgrade (select workloads for paid tiers that require compute, governance, or security features).
- Engage with an implementation partner to formalize architecture, cost controls, and automation, especially if you need rapid, low‑risk migration from legacy platforms.
For More Relevant Information
To review specific results from Databricks migrations and to discuss a tailored adoption roadmap for your organization:
- Read our case studies
- Explore our data science consulting services
- Schedule a consultation and start your journey with us
You’ll have access to the assessment of your current data platform, design a Databricks adoption plan aligned with your security and performance targets, and accelerate the transition from experiment to production.
References and sources
- Databricks documentation (general reference): https://docs.databricks.com/
- Databricks product and Lakehouse overview: https://www.databricks.com/product/data-lakehouse
- Databricks Academy (training and certifications): https://customer-academy.databricks.com/
- NYC Taxi Trip Duration dataset (example public dataset): https://www.kaggle.com/competitions/nyc-taxi-trip-duration/data
Digital Sense—company and case studies: https://www.digitalsense.ai/




