
Introduction
What is data engineering, and why has it become indispensable for modern AI-focused organizations? In today’s data-driven world, enterprises generate massive volumes of information across disparate systems—ranging from IoT and remote sensing to user behavior and enterprise logs. Data engineering is the discipline that ensures this data becomes usable, reliable, and actionable. At Digital Sense, we work with data engineering every day to keep massive datasets organized and easy to work with, so teams can focus on analyzing the data instead of fixing it.
What is Data Engineering?
Data engineering is all about building and maintaining the systems that let organizations collect, store, and process data efficiently. Think of it as the backbone that keeps information flowing smoothly from where it’s generated to where it’s actually used. It blends skills from software engineering, database design, cloud platforms, and data governance. The end goal? Making sure teams have access to high-quality, well-structured data they can trust—whether it’s for business reports, machine learning models, or real-time dashboards.
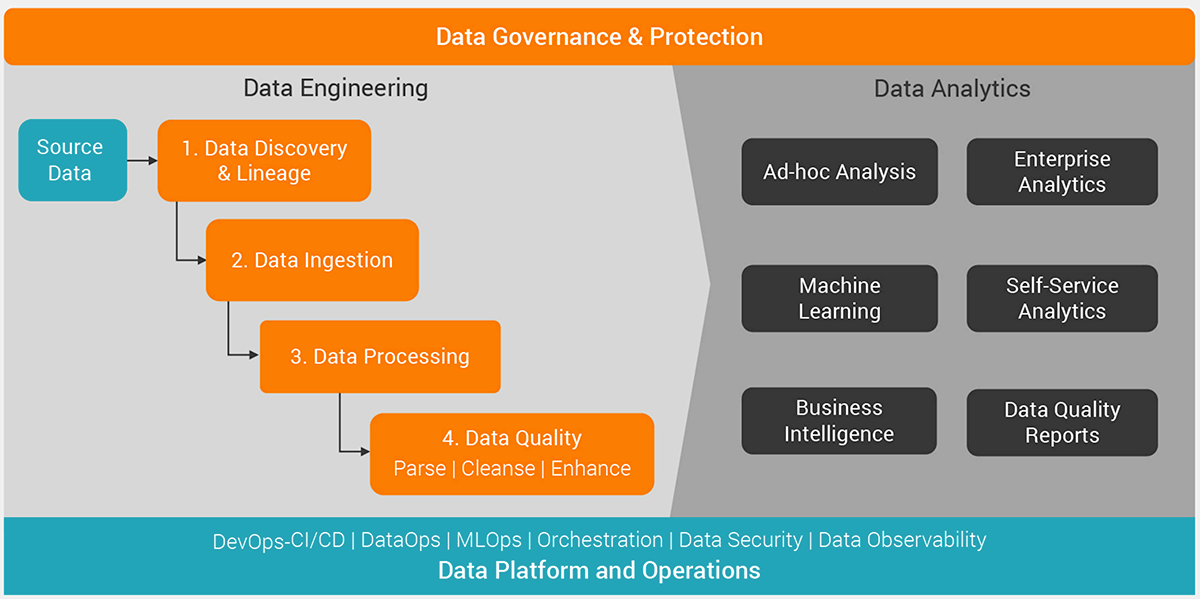
At its core, data engineering is about taking raw data—often messy, incomplete, and inconsistent—and turning it into something clean and usable for data scientists, analysts, and automated systems. This usually happens through processes like ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform), which move data from its source, clean it up, and get it ready for use. But it’s not just about moving data around—it’s also about making sure systems can handle large volumes, recover from errors, stay secure, and deliver results fast. As more organizations rely on real-time insights and AI, data engineering has become the invisible infrastructure that makes modern digital transformation work.
Key Responsibilities of a Data Engineer
Data engineers hold a broad range of responsibilities across the data lifecycle. These responsibilities are not limited to data ingestion or pipeline construction but span architecture design, data modeling, performance optimization, and compliance:
1. Data pipeline development: Designing and building ETL/ELT pipelines to ingest, transform, and load data.
2. Infrastructure management: Deploying scalable infrastructure on cloud platforms such as AWS, Azure, or GCP.
3. Data quality enforcement: Implementing validation rules, consistency checks, and alert systems to ensure clean data.
4. Monitoring and observability: Using tools to track pipeline health, data freshness, and latency metrics.
5. Data modeling: Collaborating with analysts to define schemas, dimensions, and metrics aligned with business goals.
6. Collaboration with ML teams: Providing clean, labeled, and versioned datasets for machine learning pipelines.
7. Security and compliance: Ensuring encryption, access controls, and data retention policies comply with standards such as GDPR or HIPAA.
Tools and Technologies Used In Data Engineering
A data engineer’s toolbox includes a mix of open-source frameworks, cloud services, programming languages, and commercial platforms. These tools enable engineers to automate workflows, scale systems, and maintain data integrity across environments.
Data orchestration:
- Apache Airflow: Used for scheduling and managing complex data workflows.
- Prefect: An alternative to Airflow that provides a modern, Pythonic interface.
Data processing:
- Apache Spark: Distributed computing engine for large-scale batch and streaming data.
- dbt (Data Build Tool): SQL-based transformation tool for modern data warehouses.
Storage and architecture:
- Amazon S3, Google Cloud Storage: Cloud object stores for raw and processed data.
- Snowflake, BigQuery, Redshift: Cloud-native data warehouses.
Programming languages:
- SQL: Core language for querying and transforming data.
- Python: Widely used for scripting, automation, and data transformation.
- Scala/Java/Python: Used in high-performance applications with Spark.
Monitoring and quality tools:
- Great Expectations: Framework for data validation and documentation.
- Monte Carlo: Platform for data observability and anomaly detection.
The Importance of Data Engineering in Decision-Making
Strong data pipelines make the difference between confident decisions and costly mistakes. Without data engineering, organizations risk working with outdated, incomplete, or inconsistent information—leading to bad calls or even total decision paralysis.
The impact isn’t small. According to IBM, poor data quality costs the U.S. economy around $3.1 trillion every year. That’s money lost through bad strategic planning, missed market opportunities, and higher operational risks. Reliable data engineering ensures that decision-makers get information they can trust—delivered on time and ready to use.
Data engineering helps mitigate these risks by ensuring that:
- Data is accurate: Validation steps remove inconsistencies and noise.
- Insights are timely: Automated workflows allow real-time analytics and alerts.
- AI models are effective: Models trained on well-prepared data are significantly more accurate.
- Compliance is maintained: Secure storage and access controls ensure adherence to legal requirements.
- Scalability challenges: Inadequate infrastructure can lead to performance bottlenecks and system failures as data volume grows.
Ultimately, data engineering empowers executives and product leaders to act with confidence, backed by data that is available, reliable and complete.
Conclusion
Data engineering isn’t just a nice-to-have—it’s a must for any organization that wants to compete in today’s data-driven world. From powering real-time analytics to feeding machine learning models, it’s the foundation that keeps operations running smoothly and innovation moving forward.
At Digital Sense, we’ve seen firsthand how the right data infrastructure can turn raw information into a strategic advantage. Whether it’s handling large-scale remote sensing imagery or preparing datasets for AI-powered systems, our approach ensures data is managed securely, reliably, and ready for action. This is exactly what we offer with our data science consulting services.
To learn about the next step in the MLOps pipeline learn about What is data science? To learn more about how we apply these principles in real-world use cases, explore our blog or contact us.
References
IBM: What is Data Engineering?: https://www.ibm.com/think/topics/data-engineering
Coursera: What does a data engineer do?: https://www.coursera.org/articles/what-does-a-data-engineer-do-and-how-do-i-become-one
MongoDB: Data Engineering Basics: https://www.mongodb.com/resources/basics/data-engineering
Informatica: Introduction to Data Engineering: https://www.informatica.com/resources/articles/what-is-data-engineering.html



