
This post is part of a series where Digital Sense presents key scientific contributions from our team members or collaborators, translating advanced research into insights for a broader technical audience. In this edition, we explore a new image super-resolution method developed by our colleagues and friends Charles Laroche, Andrés Almansa and Matias Tassano.
Their paper, “Deep Model-Based Super-Resolution with Non-uniform Blur”, was originally presented at the 2023 IEEE Winter Conference on Applications of Computer Vision (WACV).
Existing techniques for image super-resolution are usually limited by the kind of blur they can restore and can break completely on real-world images (e.g. action cameras). This work tackles a more realistic setting providing a key component for state of the art blind deblurring, thus paving the way for super-resolution in the wild.
What is Image Super-Resolution?
Image super-resolution (SR) is a class of techniques that reconstruct high-resolution (HR) images from low-resolution (LR) inputs. This task is central in domains such as satellite imaging, medical diagnostics, surveillance, and mobile photography, where capturing fine detail directly is often constrained by hardware, cost, or physical constraints such as low-light and/or complex motions in the scene.

Figure 1: (from the paper) Examples of super resolution results of different methods. DMBSR is the one proposed in the paper. Note that DMBSR manages to deblur different blur kernels in foreground and background.
What is a blur kernel?
At its core, super-resolution solves an ill-posed inverse problem. Multiple high-resolution images could correspond to the same low-resolution input. The problem becomes even more complex when the image is not only downsampled but also degraded by blur and noise.
To formalize it: the LR image y is generally modeled as:
\[ y=(x*k) \downarrow s + \epsilon \]
Where:
- \(x\): original HR image
- \(k\): blur kernel
- \(\downarrow_s\): downsampling by scale factor ss
- \(\epsilon\): noise
Most state-of-the-art deep learning methods assume a spatially uniform blur kernel k, often simplifying it to a Gaussian. However, this assumption rarely holds in real-world data.
Why Does It Matter?
In practical applications—whether in remote sensing satellites or handheld cameras—blur is seldom uniform, with particularly abrupt spatial variations in the latter case (dynamic scenes or out of focus images). A drone’s motion may induce directional blur; a lens focusing on an object in the foreground might cause background blur due to depth-of-field. This is known as spatially-varying blur, and until recently, it posed significant challenges for super-resolution models.
Uniform blur models fail to generalize to these real-world scenarios. Attempting to deblur first and then perform SR results in compounded errors. The two tasks are interdependent—errors in the first stage cascade into the second.
Introducing a Realistic Model
This challenge is precisely what the paper addresses. The authors introduce the first deep learning method for super-resolution that effectively handles simultaneously:
- Spatially-varying blur (SVB): A type of blur that changes across the image—for example, sharp foreground and blurred background caused by camera motion or defocus. Unlike uniform blur, SVB reflects how different regions experience different degradation patterns, making restoration significantly more complex.
- Highly anisotropic blur kernels: Blur is anisotropic when it occurs more in one direction than another—such as streaking caused by horizontal or vertical motion. "Highly anisotropic" means this directional difference is strong, making the blur more complex and harder to reverse. These kernels often occur in footage from moving platforms like action cameras, drones or cars.
- Various noise levels and scale factors: Real images are contaminated by noise that can vary in intensity depending on sensor quality and lighting. Additionally, super-resolution often involves different zoom levels (e.g., 2×, 4×), called scale factors, which directly affect the difficulty of reconstruction. A robust model must generalize across both.
The approach bridges the precision of model-based optimization with the learning capacity of deep networks, leveraging an algorithmic framework known as deep unfolded plug-and-play.
What is a deep unfolded plug-and-play framework?
Deep unfolded plug-and-play framework refers to a hybrid approach that combines the mathematical structure of model-based optimization algorithms with the learning capabilities of deep neural networks, thus providing a physically inspired neural network architecture.
Here’s how it works in this specific case:
- Traditional model-based methods for super-resolution formulate the problem as an optimization innovation i task: find the high-resolution image that best explains the observed low-resolution data, subject to prior knowledge (regularization).
- The plug-and-play strategy replaces the handcrafted prior (e.g., total variation, wavelets) with a learned deep neural network, typically a CNN trained to perform image denoising. This denoiser acts as an implicit regularizer, guiding the solution toward visually plausible images.
- In this paper, the authors use a linearized ADMM (Alternating Direction Method of Multipliers) optimization algorithm, where the denoising step is "plugged in" as a deep CNN module—hence, deep plug-and-play.
- The standard practice is to unfold this iterative algorithm into a deep network architecture: each iteration becomes a layer in the network, with trainable parameters, enabling efficient end-to-end training and fast inference with less iterations than a standard plug-and-play method.
In summary, the deep unfolded plug-and-play framework used in this work leverages the structure and convergence properties of optimization algorithms while benefiting from the expressiveness and adaptability of deep learning—resulting in a system that is both theoretically grounded and practically powerful for handling complex degradations like spatially-varying blur.
Bridging Theory and Application with Deep Plug-and-Play ADMM
The foundation of this work is an optimization algorithm based on ADMM (Alternating Direction Method of Multipliers), commonly used for inverse problems in imaging. The authors reformulate the SR problem as:
\[x^* = \arg \underset{x}{\min} || (Hx)\downarrow_s -y ||^2 + \lambda \Phi(x)\]
Where:
- \(H\) is a general spatially-varying blur operator
- \(\Phi(x)\) is a learned prior (regularization function)
- \(\lambda\) controls the regularization strength
Rather than hand-crafting priors, the authors use a deep convolutional denoiser as an implicit prior in an unfolded plug-and-play fashion. This denoiser acts as a learned regularizer during the iterative optimization steps of ADMM.
Linearized ADMM for Tractability
To handle the computational load of non-uniform blur, the authors introduce a linearized ADMM variant, avoiding the need to invert complex matrices. This key innovation enables fast, iterative updates that scale well to high-resolution images.
Deep Unfolding: Optimization Meets Deep Learning
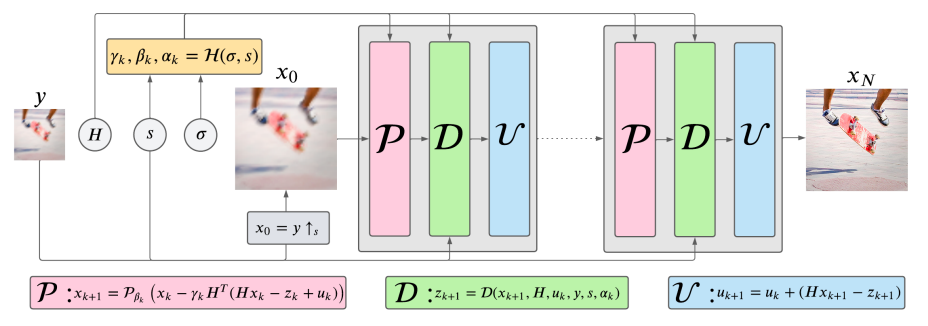
While plug-and-play optimization is powerful, it suffers from long runtimes and sensitivity to hyperparameters. To overcome this, the team uses deep unfolding—a technique that unrolls the iterative optimization into a fixed-depth neural network.
This architecture alternates between:
- P: a CNN-based denoiser module (prior enforcement)
- D: a data-fitting module (aligning with observed LR image)
- U: an update module (maintaining consistency with optimization constraints)
A separate hyperparameter prediction module dynamically adjusts learning parameters at each stage, making the system robust across different blur patterns, noise levels, and scale factors.
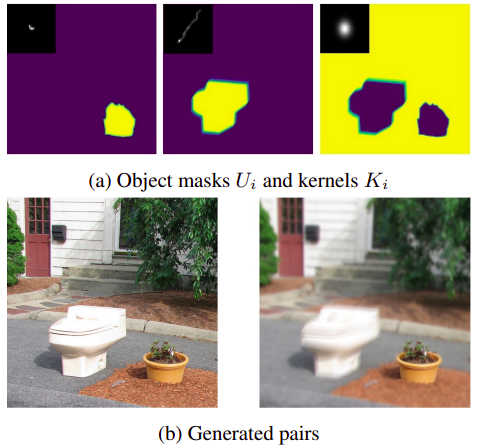
Generating Data for Complex Blurs
Training such a system requires representative data. The authors generated synthetic datasets using the COCO dataset, applying a spatially-varying blur model derived from the O’Leary approximation:
\[H=∑i=1PUiKiH = \sum_{i=1}^P U_i K_i\]
Where:
- \(KiK_i\) are different blur kernels (motion, defocus)
- \(UiU_i\) are pixel-level masks indicating where each kernel applies
This allows realistic simulation of scene-dependent blur—sharp foregrounds with blurred backgrounds or spatial mixing of blur types.
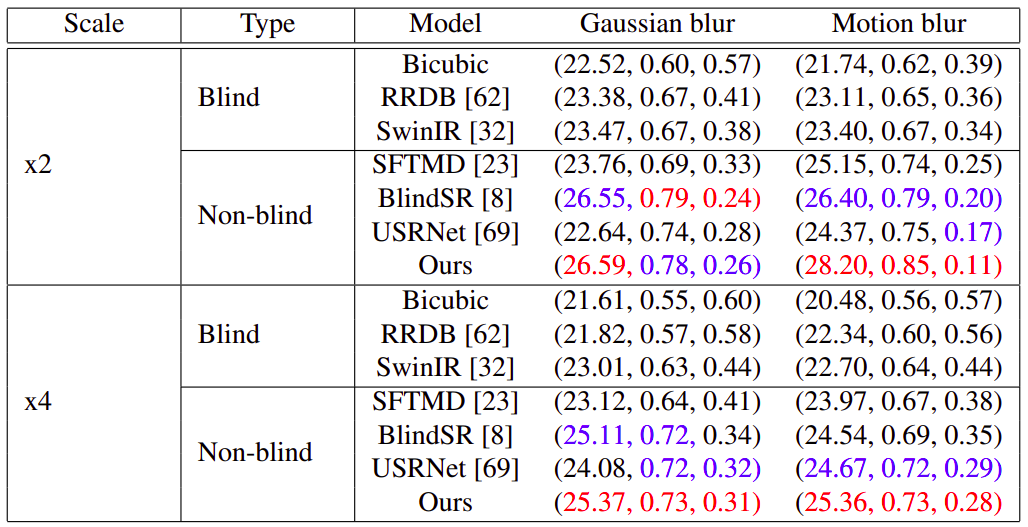
Benchmarking Results
The proposed method, referred to as DMBSR (Deep Model-Based Super-Resolution), was compared against several baselines:
Table 1. Quantitative results from the paper on synthetic data. The displayed metrics correspond respectively to PSNR↑, SSIM↑ and LPIPS↓. Best scores are displayed in red, second bests in blue.
Key Observations
- Superior Generalization: DMBSR performs well across blur types (Gaussian, motion) and scales (x2, x4).
- Efficiency: Only a single model is trained across all scenarios—no need to retrain per kernel.
- Sharpness without Artifacts: Visual inspection shows cleaner textures and reduced edge artifacts compared to SOTA baselines.

Real-World Generalization
The model was also tested on real-world data, such as defocus blur estimated from camera metadata and motion blur captured from video datasets. Despite being trained only on synthetic examples, DMBSR showed robust performance, outperforming specialized deblurring networks like MPRNet and DMPHN.
This is critical for deployment scenarios where accurate blur kernels are hard to estimate, and systems need to generalize well across hardware and conditions.
Implications for Industry Applications
At Digital Sense, we see this as a milestone in practical AI for image restoration:
- Remote Sensing: Satellite and drone imaging often suffer from motion-induced blur due to platform instability. DMBSR can significantly improve terrain and object visibility without changing the onboard hardware.
- Biomedical Imaging: Microscopy images are subject to depth-related blur. This approach enables higher-fidelity reconstructions for diagnosis.
- Media & Entertainment: Studios using action cameras or VR content can restore motion-blurred footage without post-processing artifacts.
- Surveillance: For forensic analysis, restoring license plates or facial features from low-res, blurred video can now be addressed with greater confidence. Even for smart defect recognition technology.
Conclusion
The work of our collaborators Laroche, Almansa, and Tassano exemplifies the best of applied scientific research—grounded in solid mathematical modeling, made efficient through algorithmic design, and amplified by deep learning.
Their proposed method—combining a deep plug-and-play framework with linearized ADMM and network unfolding—offers a robust and scalable solution to a longstanding challenge in image restoration: super-resolution in the presence of spatially-varying blur. It generalizes effectively across a wide range of degradations without requiring retraining, while outperforming existing approaches in both accuracy and visual quality.
This contribution sets a new baseline for practical, general-purpose super-resolution systems. It also highlights the value of integrating domain knowledge into the architecture of learning-based models—a principle we continue to apply across multiple areas of research and industry collaboration.
In an upcoming post, we’ll explore how this same methodology was extended in another scientific publication co-authored by one of our co-founders, further demonstrating its versatility and impact.
📩 Contact Us
At Digital Sense we continuously push the boundaries of what’s possible in AI and image processing.
If you’re working on complex visual data—whether in Earth observation, healthcare, agritech, or manufacturing—and need solutions that go beyond current limitations, we can help.
To explore how we can support your imaging, AI, or data science challenges, visit www.digitalsense.ai or schedule a consultation. You can also check our success stories for examples of past projects.
Reference
Laroche, C., Almansa, A., & Tassano, M. (2023). Deep Model-Based Super-Resolution with Non-uniform Blur. In Winter Conference on Applications of Computer Vision (WACV), pp. 1797–1808. IEEE. Preprint, Code




.jpg)