.jpg)
Welcome to another installment in our series where we explore some of the scientific papers authored by members of the Digital Sense team. Today, we delve into the paper, "On the Importance of Large Objects in CNN Based Object Detection Algorithms," co-authored by Ahmed Ben Saad, Gabriele Facciolo, and Axel Davy. Dr. Gabriele Facciolo is a professor at ENS Paris-Saclay and a Senior Scientific Consultant at Digital Sense. The paper, published in the Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, presents a counter-intuitive finding: focusing on large objects during training can significantly improve a model’s ability to detect objects of all sizes.
What is learning-based object detection?
Object detection is a cornerstone of computer vision. It goes beyond simply classifying what is in an image; it also determines where in the image the object is located. This dual challenge—classification and localization—has made object detection central in applications ranging from autonomous driving and satellite image analysis to security systems and robotics.
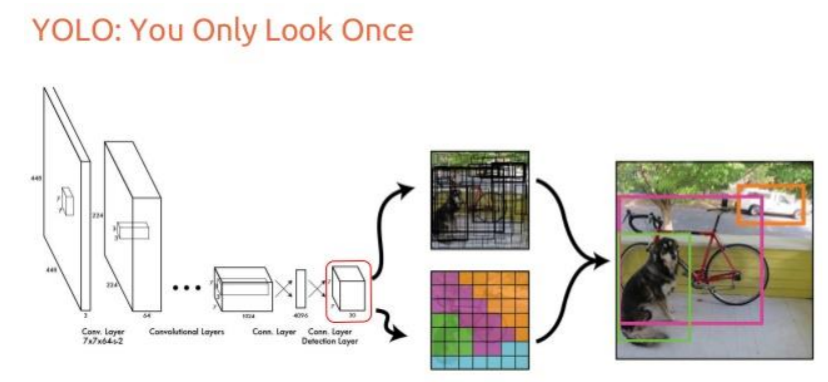
Deep Neural Networks (DNN) have revolutionized this field over the last decade. They extract visual features, learning representations that allow them to detect patterns of different scales and complexities. Modern architectures—such as YOLO (You Only Look Once), Faster R-CNN, Mask R-CNN, DETR (Detection Transformer), and InternImage—are built on neural backbones that perform exceptionally well on large-scale datasets like COCO or NuScenes.
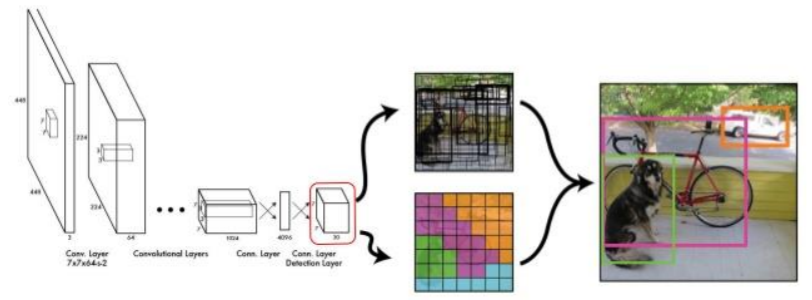
Despite their success, DNN-based detectors face a persistent challenge: the variability of object sizes. Detecting a small traffic light in a wide-angle street scene is fundamentally different from detecting a large airplane occupying half the frame. This imbalance has important consequences for both how models learn and how they perform.
Why does object size matter?
Conventional wisdom in training deep learning models might suggest that to improve small object detection, one should emphasize training on small objects. However, the research by Ben Saad, Facciolo, and Davy shows the opposite: large objects are essential for learning features that generalize across all object sizes.
Large objects contain rich textures and fine-grained details, providing the model with high-quality visual cues. These cues help the network learn robust low-level and high-level features that are also valuable when detecting small and medium objects. By contrast, small objects are often ambiguous—even for human annotators—without their surrounding context (see the figure below from the paper, where cropped traffic lights or books become almost unrecognizable without context). This means that models trained predominantly on small objects may struggle to generalize effectively.

Experimental Evidence
The authors validated this intuition with controlled experiments:
- Models pretrained only on large objects and later fine-tuned on full datasets outperformed models pretrained on small or medium objects, across all object sizes.
- For example, on the COCO dataset, pretraining on large objects before fine-tuning yielded a mean Average Precision (mAP) score of 0.350, compared to 0.296 for small/medium pretraining.
- This demonstrates that features learned from large objects are more general and transferable.
Implications for Training
This finding has direct implications for how we design datasets and training pipelines:
- Large objects, though less frequent, disproportionately improve performance across all object sizes.
- Dataset curation should ensure a healthy representation of large objects.
- Training strategies should consider weighting schemes that emphasize large objects.
The Proposed Solution: A Weighted Loss Term
Based on these observations, the authors introduced a loss re-weighting scheme that assigns more importance to large objects during training. The weighting term is a function of the object's area size, specifically the logarithm of the area, $W_i = \log(h_i \times w_i)$ where \(h_i\) and \(w_i\) are the height and width of the object’s bounding box. The logarithmic function ensures that large objects receive more weight without making smaller objects negligible.
This term is incorporated into both classification loss (deciding what the object is) and localization loss (deciding where it is). Unlike previous works that used weighting only in limited contexts, this approach applies it comprehensively.
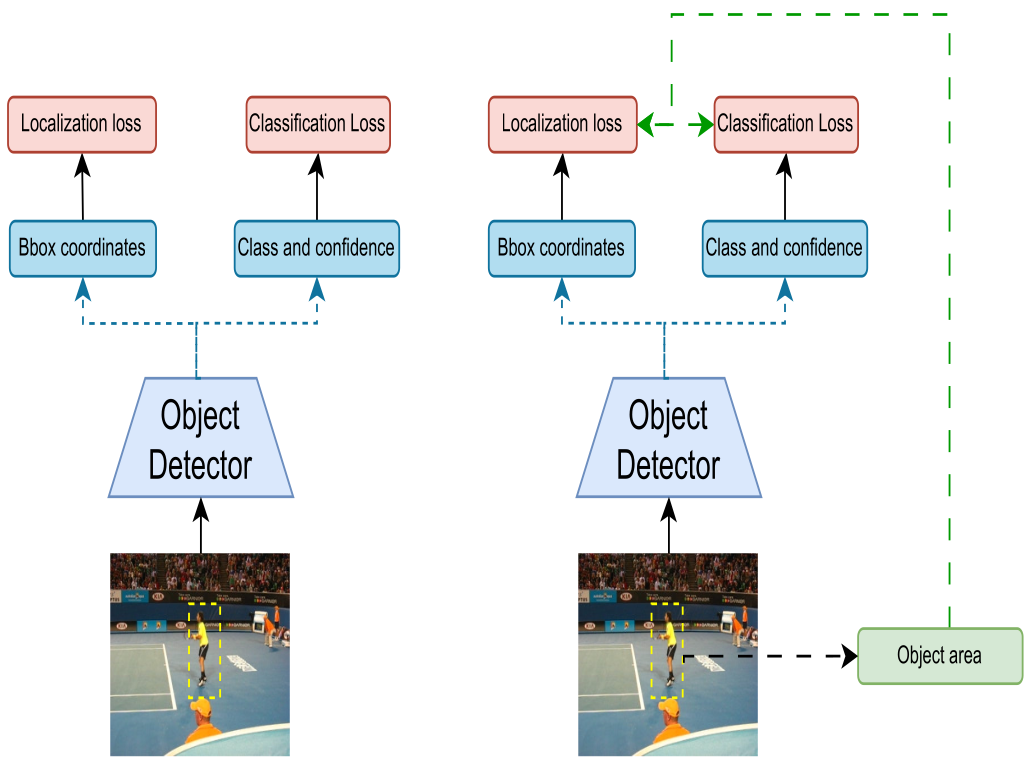
The new loss function is computed as a weighted sum over all bounding boxes in a batch, where the weight αi for each object i is proportional to its area size logarithm: $L_{\psi,\text{batch}}^{\text{new}} = \sum_{i \in B_{\text{batch}}} \alpha_i L_{\psi}(i, \hat{i})$, where \(\alpha_i = \frac{W_i}{\sum_{k=1}^{N_b} W_k}\).
This approach addresses the dataset bias present in the considered datasets (COCO and NuScenes) toward smaller objects by explicitly giving larger objects more prominence during training.
Effects on Training
To understand how the weighting term works, the authors analyzed its effect on the model's gradients. This analysis showed that this shift in focus most significantly impacts the low-level features of the network, particularly in the first blocks.
This suggests that large objects help the model learn more generic and distinguishable low-level features that are beneficial for all scales. The performance improvements are observed from the very beginning of the training process, indicating that this weighting policy helps the model find better local minima and steers the training in a more optimal direction.
Results Across Models
The proposed weighting scheme was tested on several DNN-based object detectors, including YOLO v5, InternImage, DETR, and Mask R-CNN, using the COCO and NuScenes datasets. The results consistently showed a significant improvement in performance across all models and all object sizes when the weighted loss was used.
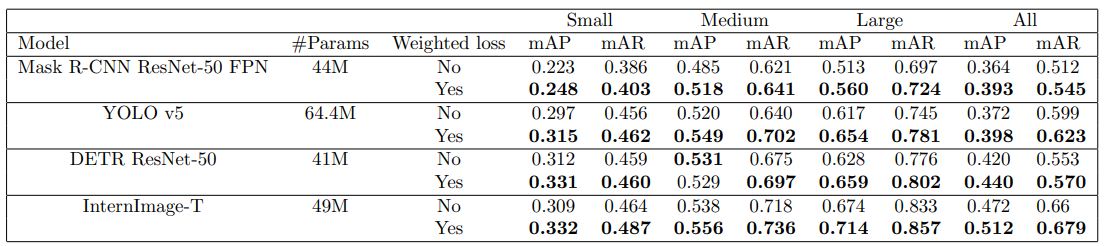
- On COCO 2017 validation, InternImage-T improved from 47.2% to 51.2% mAP—a 4 percentage point gain, surpassing larger variants of the model trained without weighting.
- YOLOv5 saw improvements from 37.2% to 39.8% mAP.
- Improvements were observed across all object sizes, with especially notable gains for small and medium objects.
These results show that focusing on large objects during training not only improves detection of large objects themselves but also strengthens performance for smaller ones.
A qualitative comparison in the figure below further demonstrates this improvement.

Conclusion: A New Perspective on Object Detection Training
The research presented in this paper provides a new perspective on training DNN-based object detectors. It demonstrates that features learned from large objects are not only important for their own detection but also for improving the model's performance on smaller and medium-sized objects. The proposed loss reweighting scheme, which gives more importance to large objects, is a simple and effective method for improving detection performance across the board.
This work highlights a critical insight: when building a dataset, ensuring a significant proportion of large objects is essential. If not, a weighting factor can be used to compensate. This approach can be seen as a corrective measure for the dataset bias and a way to steer the training process toward learning more generic, higher-quality features.
📩 Contact Us
As a company built for innovation, Digital Sense is aware and involved in the latest AI research. This paper is just one example of how our team members apply deep academic and scientific knowledge to solve real-world problems in computer vision and other AI domains.
If your organization faces complex challenges in computer vision, data science, or machine learning, we invite you to explore our capabilities further. To explore how we can support your imaging, AI, or data science challenges, visit www.digitalsense.ai or schedule a consultation. You can also check our success stories for examples of past projects.
Reference
Ben Saad, Ahmed, Gabriele Facciolo, and Axel Davy. "On the importance of large objects in CNN based object detection algorithms." Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2024.





{kind=link}